Preamble
This is a writeup on some of the problems I worked through as practice on the PicoCTF platform. This doesn’t encapsulate everything that was achieved, but rather a narrow selection of problems. In this particular instance, all of the problems came from the PicoCTF 2021 contest.
Cookies
This problem presents a web app that allows the attacker to enter an arbitrary string into a search bar. As a web problem (and hinted via the name), examining the given cookie shows an arbitrary key name of name set to 0.
I noted also that the web app came with a default pre-populated answer “snickerdoodle”. When I submitted that value, the cookie name was set to 1. Furthermore, entering a blatantly wrong answer (such as “asd”) returned a name of -1.
By altering the cookie (either by intercepting the request via Burpsuite or using a cookie editor such as the Cookie Quick Manager Firefox browser extension) we can increment the value of name to 2 and see it returns a different page (in this case “oatmeal raisin”). Iterating over the name values reveals the flag at name=18.
Scavenger Hunt
This problem engages with the attacker to explore various facets of a given website for information. Navigating to the problem presents a web app with a basic 2-button interface. By clicking the What button, we are informed that the website was constructed using HTML, CSS, and Javascript.
Hitting f12 within Firefox brings up the developers tools which allows us to view all 3 of these aspects. Clicking through Inspector reveals HTML comment code with the first portion of the flag. Clicking through Style Editor reveals CSS comment code with the seconds. Clicking through Sources shows a custom javascript file with the unusual comment, “How can I keep Google from indexing my website?”.
Googling this question reveals that some websites employ the use of a /robots.txt page to deny web crawlers from indexing specific pages. By navigating to /robots.txt on the web app, we find the third portion of the flag and yet another comment: “I think this is an apache server…can you Access the next flag?”
Googling the suggested keywords reveal that Apache servers use .htaccess files to configure details of their web sites. Navigating to /.htaccess reveals the fourth part of the flag with yet another comment: “I love making websites on my Mac, I can Store a lot of information there.”
Googling the suggested keywords reveal that the Apple macOS uses .DS_Store files to store custom attribute information. Navigating to /.DS_Store reveals the final part of the flag.
Transformation
This problem exercises creativity, math, and a relatively basic understanding of python programming. We are provided a file (enc) that contains a string of unicode characters. Furthermore, we are presented with what appears to be the original python script used to presumably encode the flag into the received unicode string.
''.join([chr((ord(flag[i]) << 8) + ord(flag[i + 1])) for i in range(0, len(flag), 2)])
The code is a simple one-liner that performs the following functions:
- It loops through the entirety of the original (unknown) flag string, starting with the first character and skipping every other character; this is what the for-loop and range() calls are performing.
- For each character that is examined in the loop…
- …It converts the character to an integer using ord(), then bit-shifts that number to the left by 8 positions. A left bit shift simply moves all the bits in the array to the left, thereby changing the number (for example, 0010 becomes 0100; in decimal, this change converts “2” to a “4”)
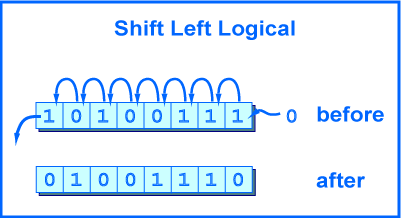
- …it also the converts the next character in the flag string to an integer using ord()
- …finally, it adds the 2 integers together and then converts the result back to a unicode character, joining the characters together into a single string.
To solve this problem, we can note the following:
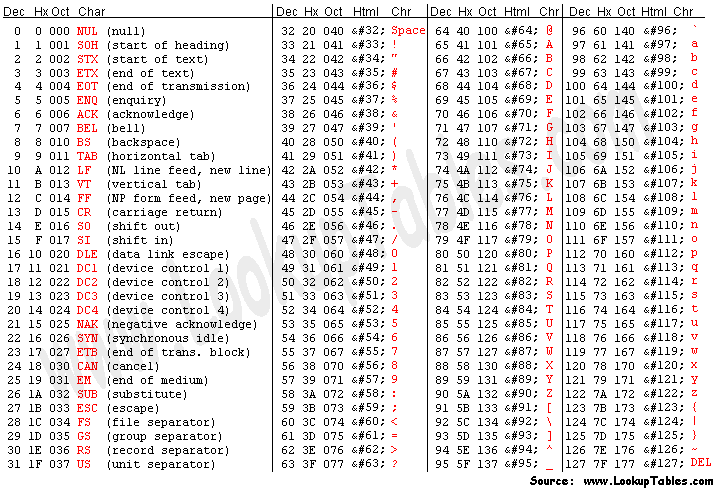
Among the possible ASCII characters that exist, we know that the flag won’t be composed of the first 32 (or 0-31). Therefore, the number of possible characters exist as decimal values between 32 and 127. Moreover, if we were to bit-shift any 2 sequential ASCII characters 8 positions to the left (as was done in the encryption algorithm), we would note that there is a 256 integer “gap” that forms between them. With such a wide delta (compared to the narrow 95 integer gap that exists between Space and ~) this means that there can only be 1 correct pairing when the bit-shift character is added to an unmodified one.
For example if the first 2 characters are ‘p’ and ‘i’, then the following would take place:
‘p’ has a decimal value of 112, which is bit shift to 28672.
‘i’ has a decimal value of 105.
When added together, they yield 28777. If I try to decrypt with a bit-shift value of ‘o’ or ‘q’ (28416 and 28928, respectively) these would result with values incompatible with ASCII:
28777 - 28416 = 361
28777 - 28928 = -151
Therefore, in order to decrypt the enc file, we need to loop through each unicode character and convert them to an integer with ord(). Then, for each of these values, we want to try subtracting bit-shifted characters from SPACE to ~ until we yield a result in the range of 32 to 126. This provides the current character and the subsequent one.
flag = "灩捯䍔䙻ㄶ形楴獟楮獴㌴摟潦弸彥㜰㍢㐸㙽"
for n in range(0, len(flag)):
ascii_10 = ord(flag[n])
for m in range(32, 127):
shift = m << 8
leftover = ascii_10 - shift
if (leftover < 127 and leftover > 32):
ans = ans[:len(ans)] + chr(m)
ans = ans[:len(ans)] + chr(leftover)
else:
continue
print(ans)
The output of the above code provides the flag.